Let datafruit learn your company
Connect sources like cloud providers, GitHub, Kubernetes Clusters, and Observability.
Ask it anything!
Describe what you need in plain English. It plans and executes across your stack.
Watch it get to work
Datafruit was made to work with tools like Kubernetes and Terraform. It executes actions safely with guardrails that you can set.
Check its Work
Datafruit only makes changed in ways that you can audit. After it's done you can review it's work.
Datafruit lives in your cloud
We embed directly into the tools you use. Datafruit natively integrates with the AWS, GCP, Azure, GitHub, and more!
Let datafruit learn your company
Connect sources like cloud providers, GitHub, Kubernetes Clusters, and Observability.
Agents with boundaries,
security you can trust
Datafruit is designed to meet the demands of modern security requirements — safe by default, scalable, and ready to integrate with your existing engineering tools.
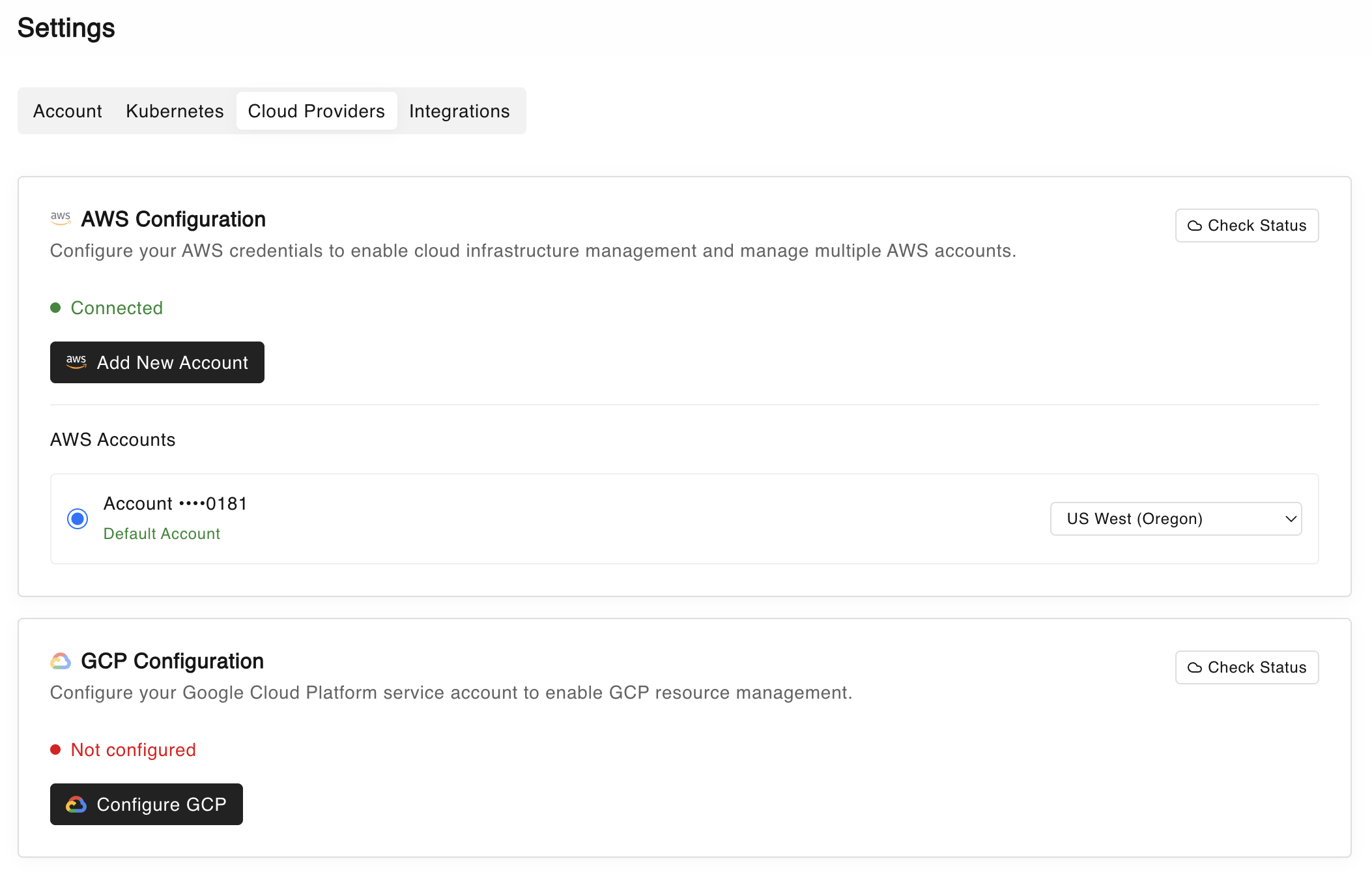
You decide what the agent can do
Agents operate only within the boundaries you define. Users can:
- Explicitly scope which accounts, clusters, or repos an agent can access
- Set read-only vs. write permissions
- Require approval flows for sensitive operations
- Blacklist and Whitelist different commands.
Building trust through standards
We’re actively pursuing SOC 2 Type II certification to validate our security posture. In the meantime, we follow industry best practices:
- Encryption in transit and at rest
- Least privilege for all integrations
Agents with boundaries,
security you can trust
build faster with datafruit
book a call